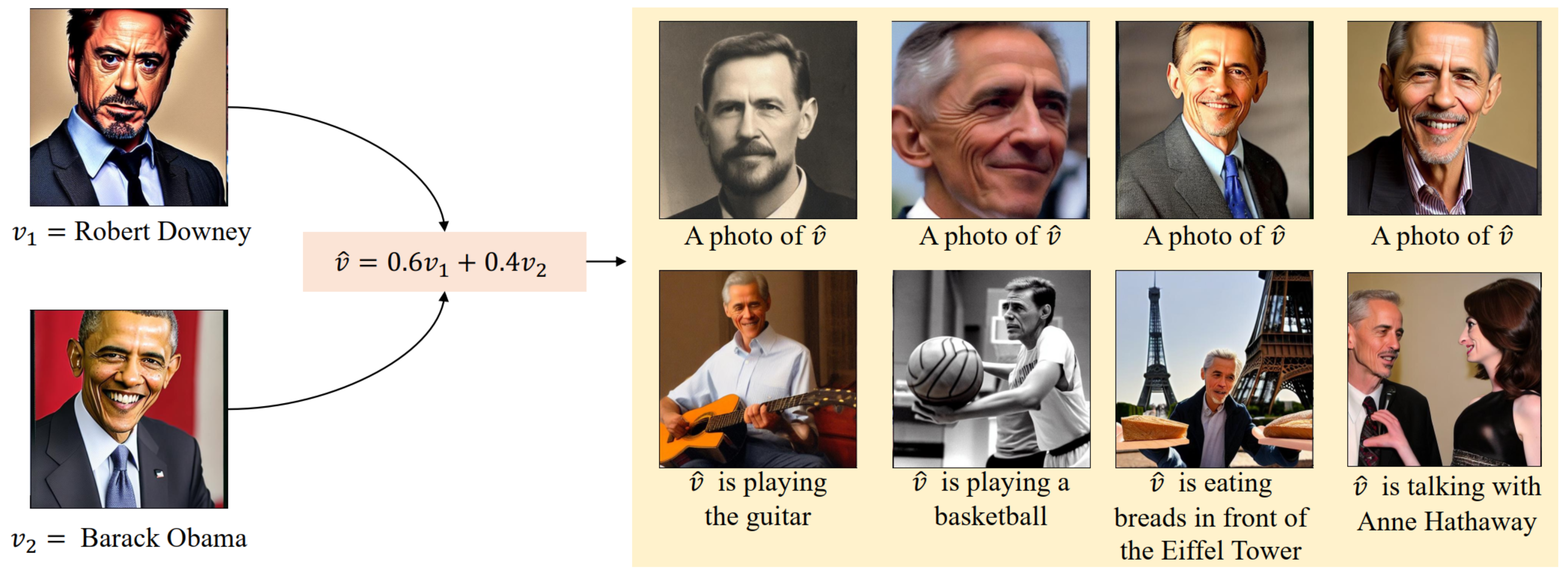
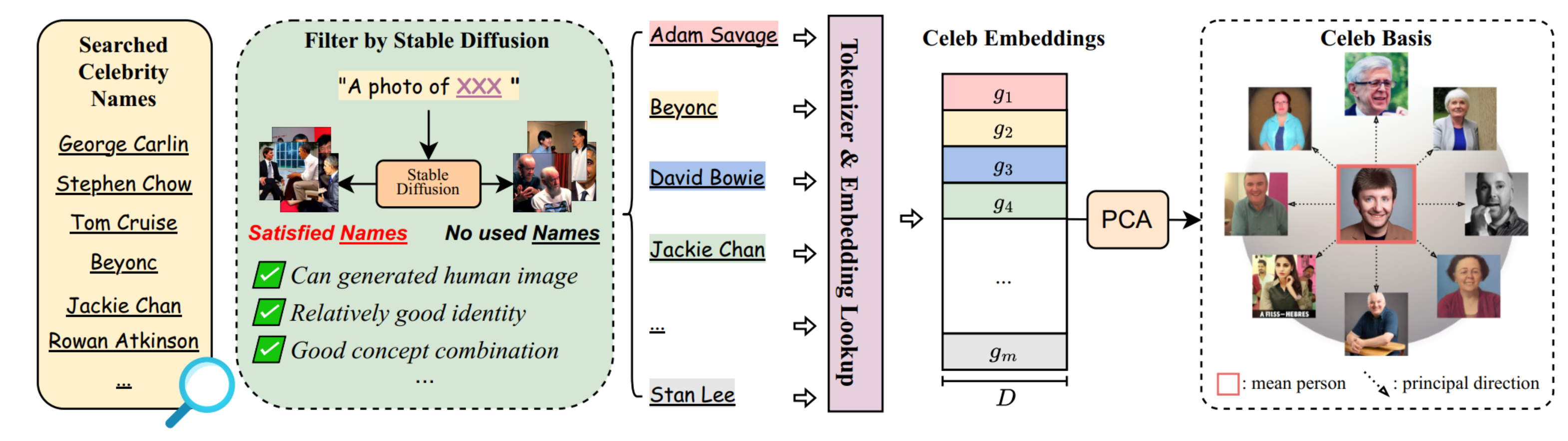
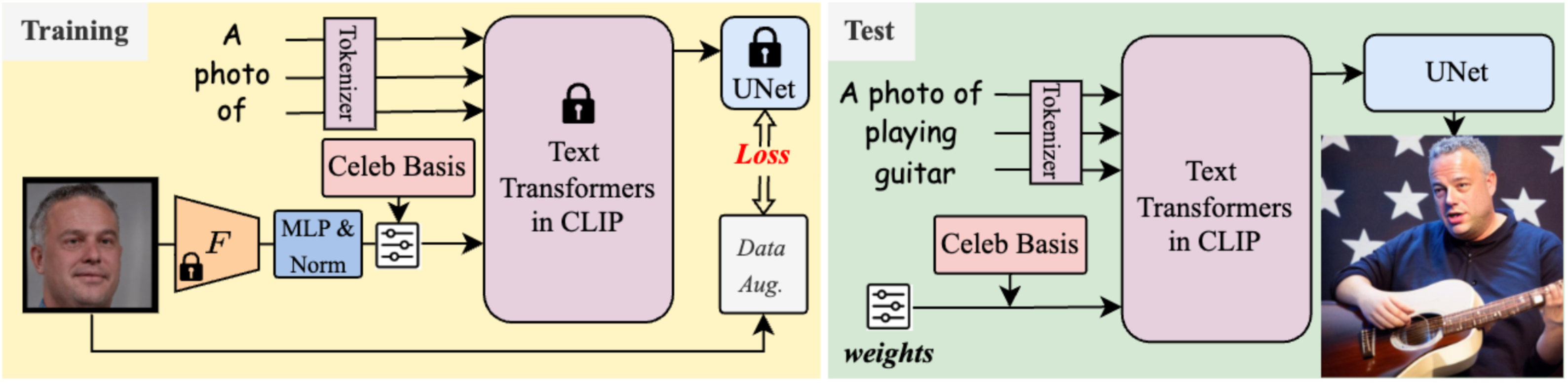
TL;DR: Intergrating a unique individual into the pre-trained diffusion model with:
✅ just one facial photograph ✅ only 1024 learnable parameters ✅ in 3 minutes tunning ✅ Textural-Inversion compatibility ✅ Genearte and interact with other (new person) concepts